There’s something magical about building in VR. Imagine being able to assemble weightless car engines, arrange dynamic virtual workspaces, or create imaginary castles with infinite bricks. Arranging or assembling virtual objects is a common scenario across a range of experiences, particularly in education, enterprise, and industrial training – not to mention tabletop and real-time strategy gaming.
Imagine being able to assemble weightless car engines, arrange dynamic virtual workspaces, or create imaginary castles with infinite bricks. Click To TweetFor our latest interaction sprint, we explored how building and stacking interactions could feel seamless, responsive, and stable. How could we place, stack, and assemble virtual objects quickly and accurately while preserving the nuance and richness of full physics simulation? Check out our results below or download the example demo from the Leap Motion Gallery.
The Challenge
Manipulating physically simulated virtual objects with your bare hands is an incredibly complex task. The advanced hand-based physics layer of the Leap Motion Interaction Engine makes the foundational elements of grabbing and releasing virtual objects feel natural. In itself this is already a feat of engineering and interaction design.

Nonetheless, the precise rotation, placement, and stacking of physics-enabled objects – while very much possible – takes a deft touch. Stacking in particular is a good example.

Stacking in VR shouldn’t feel like bomb defusal.
When we stack objects in the physical world, we keep track of many aspects of the tower’s stability through our sense of touch. Placing a block onto a tower of objects, we feel when and where the held block makes contact with the structure. In that instant we feel actual physical resistance. This constant stream of information lets us seamlessly adjust our movements and application of force in a feedback loop – so we don’t unbalance the tower.
The easiest way to counteract these issues in VR is to disable physics and simply move the object meshes around. This successfully eliminates unintended collisions between the held object and others, as well as accidental nudges.

With gravity and inertia disabled, we can assemble the blocks however we want. But it still looks weird!
However, this solution is far from ideal, as precise rotation, placement, and alignment are still challenging. Moreover, disabling physics on virtual objects makes interacting with them far less compelling. There’s an innate richness to physically simulated virtual interactions in VR/AR that’s only amplified when you can use your bare hands.
A Deployable Scaffold
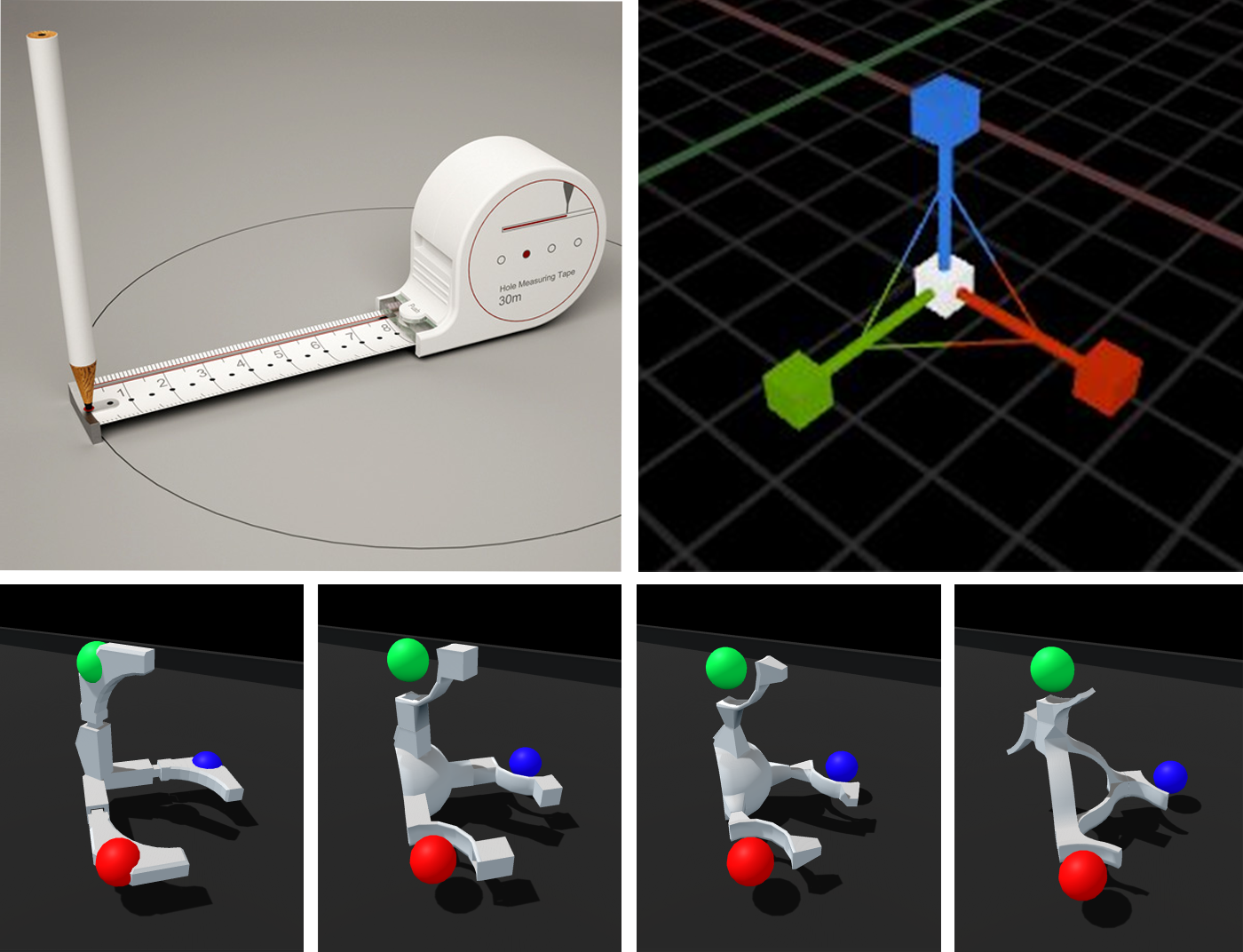
The best VR/AR interactions often combine cues from the real world with the unique possibilities of the medium. Investigating how we make assembling things in the physical world easier, we looked at things like rulers and measuring tapes for alignment and the concept of scaffolding – a temporary structure used to support materials in aid of construction.


Snappable grids are a common feature of flat-screen 3D applications. Even in VR we see early examples like the very nice implementation in Google Blocks.

Deployable scaffolding in VR lets you rapidly create interactive spaces where the rules of physics (temporarily) don't apply. Click To TweetHowever, rather than covering the whole world in a grid, we proposed the idea of using them as discrete volumetric tools. This would be a temporary, resizable three-dimensional grid which would help create assemblies of virtual objects – a deployable scaffold! As objects are placed into the grid, they would snap into position and be held by a physics spring, maintaining physical simulation throughout the interaction. Once a user was done assembling, they could deactivate the grid. This releases the springs and returns the objects to unconstrained physics simulation.
To create this scaffolding system we needed to build two components: (1) a deployable, resizable, and snappable 3D grid, and (2) an example set of objects to assemble. As we investigated this concept further it became clear that the grid itself would require quite a bit of engineering, especially for a sprint timeline.
Generating A 3D Grid
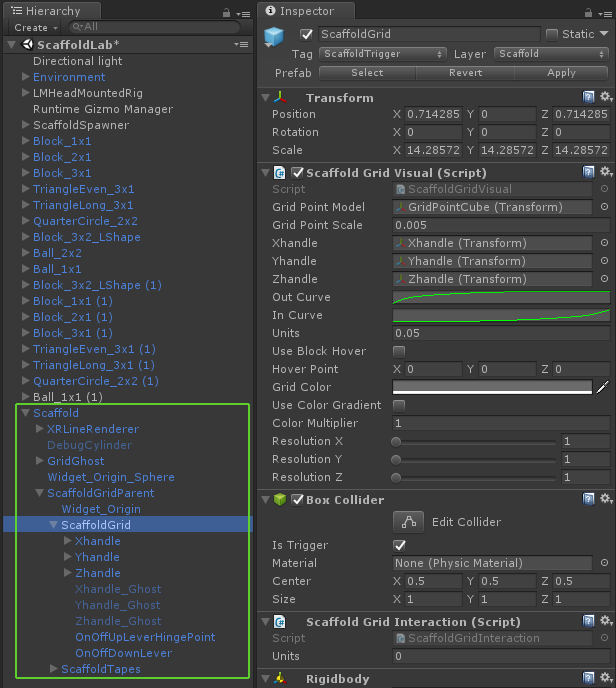
Building the visual grid around which Scaffold interactions are centered is straightforward – instantiate a 3D array of objects representing points of the grid using a simple prefab as a template. For this we created a ScaffoldGridVisual class. We keep the visual grid features of the Scaffold separate from the interactive features for flexibility and organization. Here we expose the basic parameters such as the scale for the point meshes and the size of each grid unit expressed in world units.
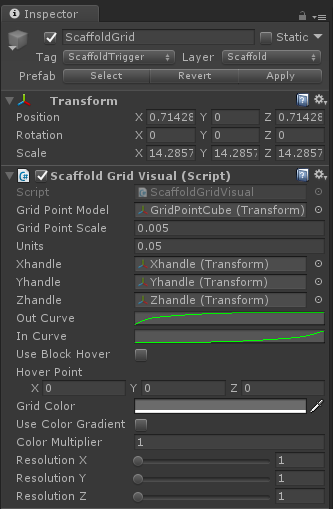
But while the array of grid points is easy to create, it’s also clear that we need to optimize at the outset. Since we want to be able to change the dimensions of a Scaffold dynamically, we may have many of them per Scaffold (and potentially multiple Scaffolds per scene). So simple static batching isn’t an optimization path in this case.
This made it worthwhile to create a custom GPU-instanced shader to render the points in our Scaffold grid. This type of repetitive rendering of identical objects is great to put onto the GPU – it saves CPU cycles and keeps our framerate high. For setup, we only need to ensure that the prefab for your grid point mesh has a material that uses our GPU instanced shader.
In the early stages of development it was helpful to color-code the dots. Since the grid will be dynamically resized, colors are helpful to identify what we’re destroying and recreating or whether our dot order is orderly. (Also it was pretty and we like rainbow things.
Shader-Based Grid Hover Affordance
In our work we strive to make as many things as possible reactive to our actions – heightening the sense of presence and magic that makes VR such a wonderful medium. VR lacks many of the depth cues that we rely on in the physical world, so reactivity is also important in boosting our proprioception (i.e. our sense of the relative positions of different parts of our body).
With that in mind, we didn’t stop at simply making a grid of cubes. Since we render our grid points with a custom shader, we could add features to our shader to help users better understand the position and depth of their hands.
In the shader, we add a 3D vector for a hover position. As we render each vertex of each cube in the grid array, we can scale out the position of each vertex based on its distance from our hover position. Then, in our ScaffoldGridVisual class, we can use the Leap Motion API to get a fingertip position, using it to set the value for our custom “_HoverPosition” variable in the material for our grid point cubes. We can also use the same hover position within the shader to ramp up the color of a vertex based on the same distance as well.
The result is that our grid points will grow and glow when your hand is near – making it more responsive and easy to use.

Saving Object Positions
With the visual portion of our grid underway, it’s time to build the interactive features. For this, we created a ScaffoldGridInteraction class to sit next to the ScaffoldGridVisual class in our prefab hierarchy. This class has two main duties: maintain a record of which objects have been placed in which grid locations, and find the nearest grid location to an object as it is hovered.
For a record of the objects current in the Scaffold and their grid positions, a simple Dictionary variable is created in the class. This holds a Vector3 to store which grid position the object occupies, and a ScaffoldBlockData data type. ScaffoldBlockData is a custom struct that holds what we need to know about each object:
- its Transform
- its local position relative to the grid’s parent transform
- its local rotation
The cool part here is that when the Scaffold is empty, so is the Dictionary. It only needs an entry for each object – which means we don’t have to have a large empty data array when there are no objects in the Scaffold. Entries to the Dictionary are added when an object is placed and removed when it is grasped again.
Making Scaffold-Reactive Blocks & Their Ghosts
Creating objects that can be placed within (and aligned to) our new grid starts with adding an InteractionBehaviour component to one of our block models. Combined with the Interaction Engine, this takes care of the important task of making the object graspable. To empower the block to interact with the grid, we created and added another Monobehaviour component that we called ScaffoldBehaviour. This behavior handles as much of the block-specific logic as possible so the grid classes stay less complicated and remain wieldy (yes, it’s a word).
As with the grid itself, we’ve learned to think about the affordances for our interactions right along with the interactions themselves. The ScaffoldBehaviour handles interaction logic such as changing physics settings while we grab, place, and release/drop our blocks. But this class also creates and manages a ghost of the block when it’s within the grid. The ScaffoldBehaviour:
- Spawns the transparent ghost model when the block is grasped and enters the grid’s box collider
- Places the ghost at the grid location nearest to the grasping hand
- Rotates the ghost to the nearest orthogonal rotation to the block relative to the grid
- Checks to see if the ghost is intersecting any block already in the grid, and if so, changes the ghost color.
When the block is ungrasped within the grid, it is placed and rotated similarly to the grid and the ghost is destroyed. Additionally we add another class, ScaffoldBlockAffordance, to the block to handle the various appearance changes triggered – hovering, grasping, and placing the blocks. (More on this in a bit.)

Resizing The Grid with Interaction Engine Handles
By building handles to grasp and drag, a user can resize the Scaffold to fit within a specific area. We created spherical handles with Interaction Engine behaviors, which we constrained to the move in the axis they control. The ScaffoldGridVisual class has references to these handles. As they’re dragged, the ScaffoldGridVisual rebuilds the grid dynamically.
As this happens, the ScaffoldGridVisual checks the Dictionary from the ScaffoldGridInteraction class to see if there are blocks in grid point as the grid point is created or destroyed. If so, the AddBlockToGrid() or RemoveBlockFromGrid() methods in that block’s ScaffoldBehaviour class are called as needed.
This valuable functionality unlocks a nice variety of playful and emergent interactions. This way, if the user places blocks in the Scaffold and drags the handles to make the grid smaller, the blocks are released, dropping them. Conversely, if the handles are dragged to make the grid larger, and blocks had been placed at those grid points, then the blocks snap back into place!
Widget Stages, States, and Shapes
Now that we have a resizable 3D grid with the ability to show ghosted object positions before snapping them into place, it’s time to bundle this functionality into a widget. We wanted to be able to use multiple Scaffolds and to be able to let go of a Scaffold widget, have it animate to the nearest surface, auto-align, and auto-expand its handles on landing. (Phew!) To manage all of the state changes that come with this higher-level functionality, we created a Scaffold class to sit at the top of the hierarchy and control the other classes.
For this functionality, we have a simple state machine with four states:
- Anchored: All of the Scaffold’s features are hidden expect for its graspable icon.
- Held: The Scaffold’s grid and handles are shown. We run logic for finding a suitable surface.
- Landing: When the Scaffold is let go, it animates and aligns to the closest surface.
- Deployed: This is the main, active state for the Scaffold grid and its handles.
The top-level Scaffold class has references to three classes – ScaffoldGridInteraction, ScaffoldGridVisual, and ScaffoldHandle. Its finite state machine controls the activation and deactivation of all these classes as needed as the state change. The Scaffold component’s transform, along with all of its child transforms and their components, is then dragged to a prefab folder to become our Scaffold widget.
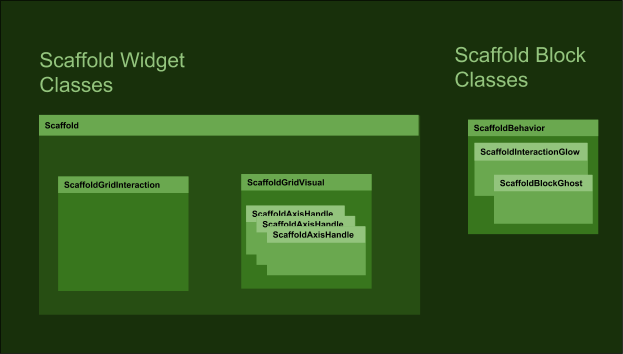
The hierarchy for the finished widget shows how the classes from the diagram above sit together in the Unity scene.
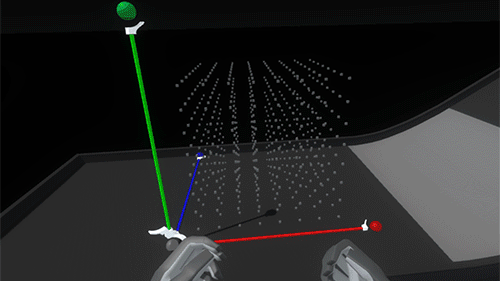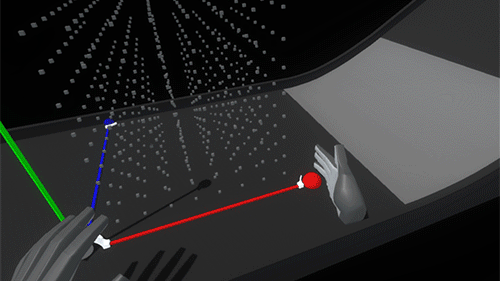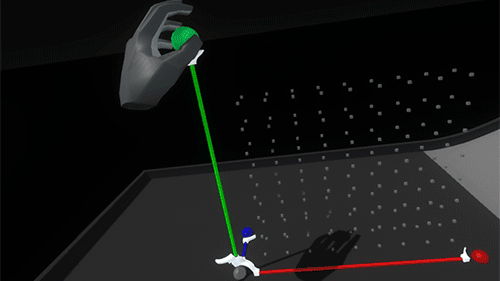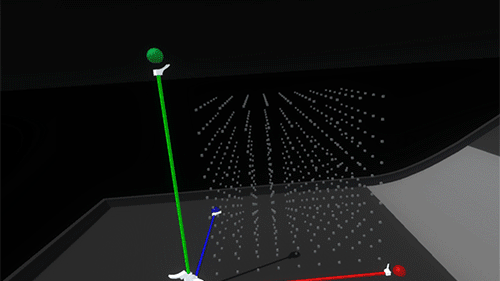
The pre-deployment anchor stage is the fully contracted state of the grid when it might be attached to a floating hand menu slot or placed somewhere in the environment, ready to be picked up. In this state we reduced the widget to a 3D icon, just three colored spheres and a larger white anchor sphere.

Once you pick up the icon widget, we move into the holding/placing state. The icon becomes the full featured widget, with its red, green and blue axis handles retracted. While holding it, we raycast out from the widget looking for a suitable placement surface (defined through layers). Rotating the widget lets you aim the raycast.
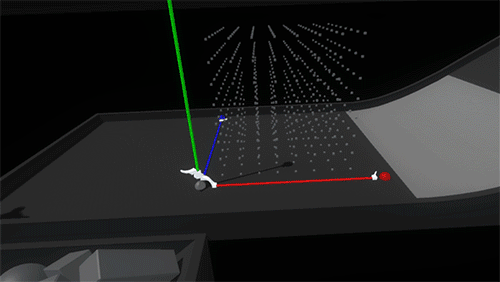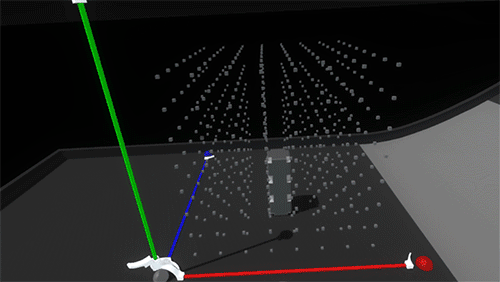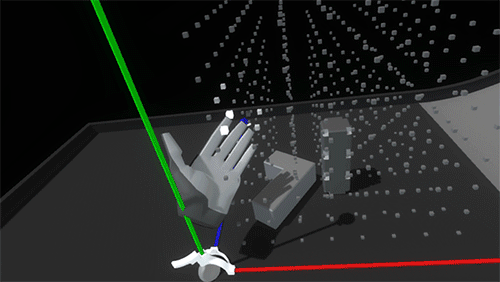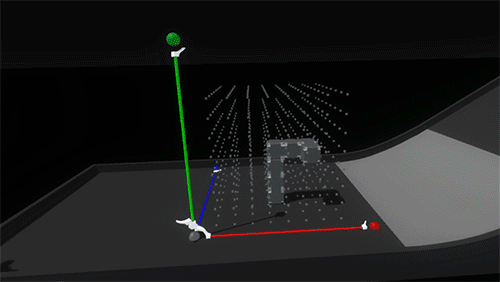
When a hit is registered, we show a ghosted version of the expanded widget, aligned to the target surface. Letting go of the widget while pointed toward a viable surface animates the widget to its target position and then automatically expands the axes, generating a 3D scaffold.

The deployed widget needed a few features: the ability to resize each axis by pushing or grabbing the axis handles, a way to pick up the whole scaffold and place it somewhere else, and the ability to deactivate/reactivate the scaffold.
The shape of the widget itself went through a couple of iterations, drawing inspiration from measuring tapes and other handheld construction aids as well as software-based transform gizmos. We honed in on the important direct interaction affordances of the axis handles (red, green, and blue), the anchor handle (white), and the implied directionality of the white housing.
The colored axis handles can be pushed around or grabbed and dragged:
The whole widget and scaffold can be picked up and relocated by grabbing the larger white anchor handle. This temporarily returns the widget to the holding/placing state and raycasts for new viable target positions.
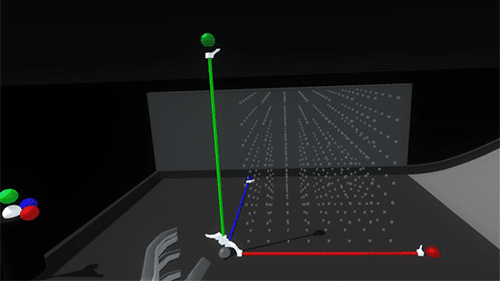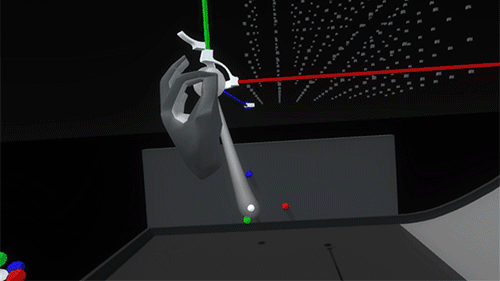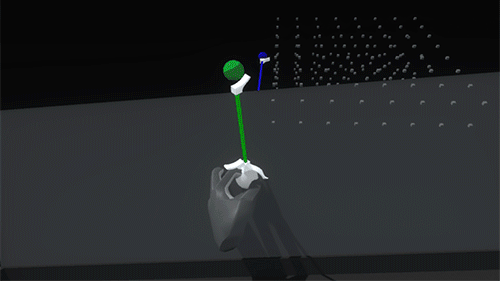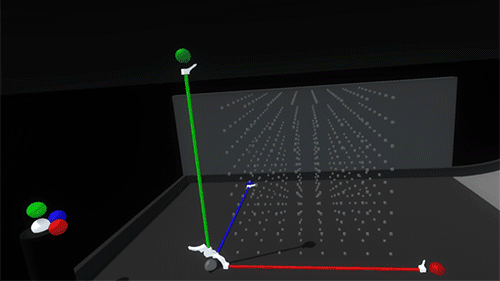
And with a flick of a switch the axes can be retracted and the whole scaffold deactivated:
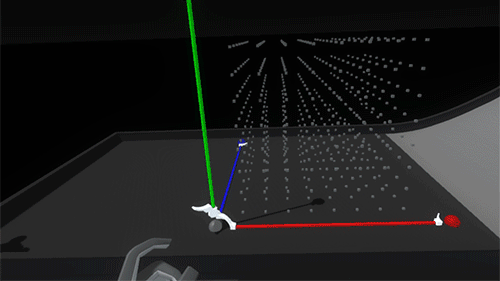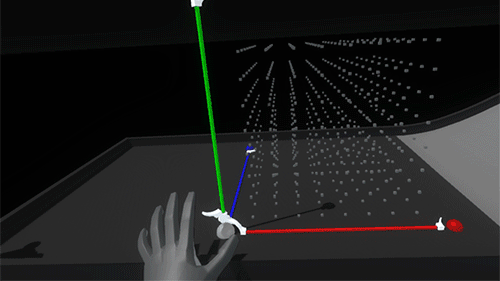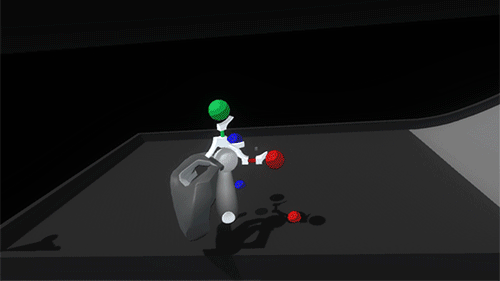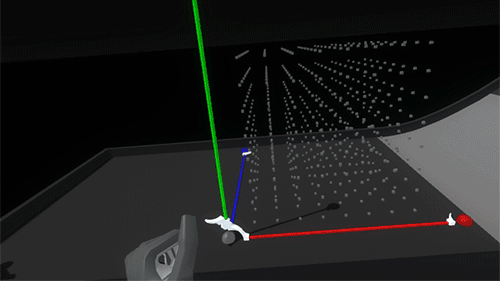
Now we finally get to the fun part – stacking things up and knocking them down! The grid unit size is configurable and was scaled to feel nice and manageable for hands – larger than Lego blocks, smaller than bricks. We modeled some simple shapes and created a little sloped environment to set up and knock down assemblies. Then we worked towards a balance of affordances and visual cues that would help a user quickly and accurately create an assembly without feeling overwhelmed.
When your hand approaches any block, its color lightens slightly, driven by proximity. When you pick one up it will glow brightly with an emissive highlight, making the ‘grabbed’ state very clear:
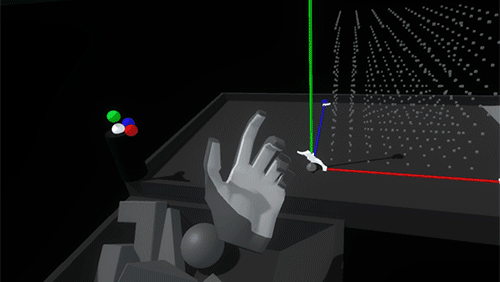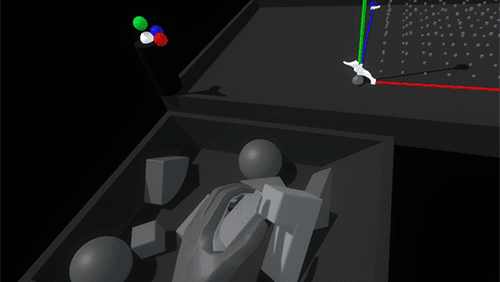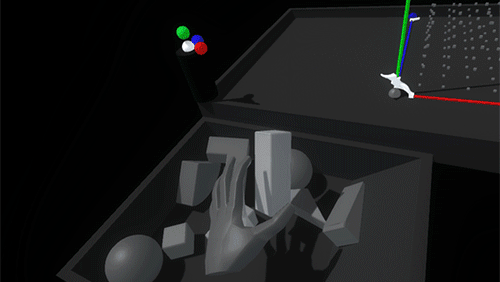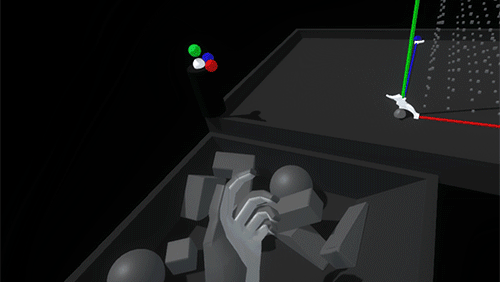
As you bring a held block into the grid, a white ghosted version of it appears, showing the closest viable position and rotation. Releasing the block when the ghost is white will snap it into place. If the ghost intersects with an occupied space, the ghost turns red. Releasing the block when the ghost is red simply won’t snap the block into the grid, letting it drop from your hand.
Once a block is snapped into the grid, notches animate in on their corners to emphasize the feeling that they’re being held in place by the scaffold. When the lever to deactivate the grid is flipped and the scaffold axes contract, the block’s notches fill in and the blocks return to their normal resting state.

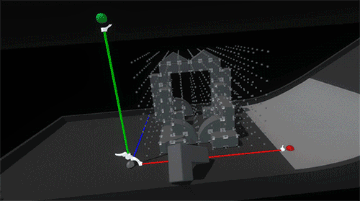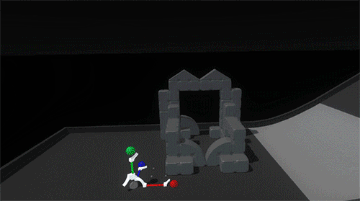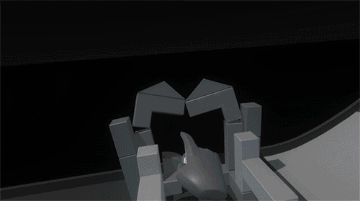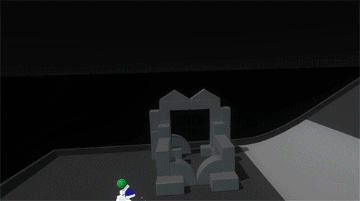
The last piece, and perhaps the most important, was tuning the feeling of physicality throughout the entire interaction. For reference, here’s what it looks like when we disable physics on a block once it’s snapped into the scaffold.
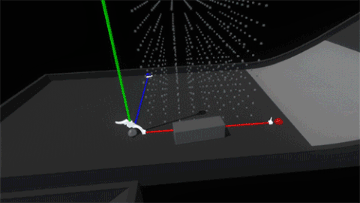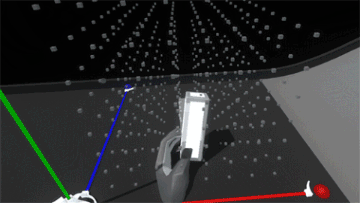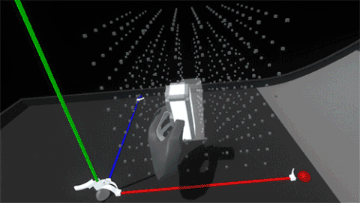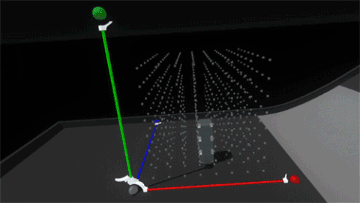
Interaction (or lack thereof) with the block suddenly feels hollow and unsatisfying. Suddenly switching the rules of interactivity from colliding to non-colliding feels inconsistent. Perhaps if blocks became ghosted when placed in the grid, this change wouldn’t be as jarring… but what would happen if we added springs and maintain the block’s collidability?
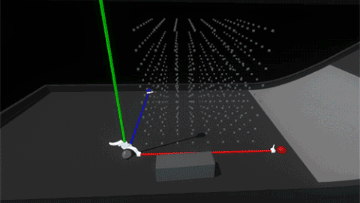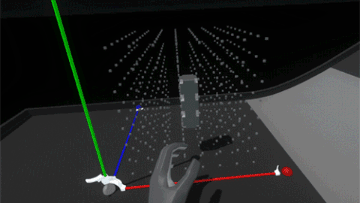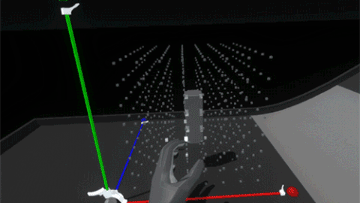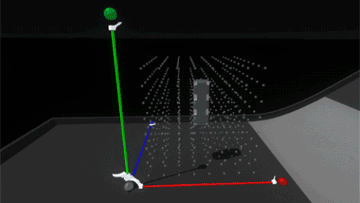
Much better! Now it feels more like the grid is a structured force field that holds the blocks in position. However, since the blocks also still collide with each other, when the assembly is strongly disturbed the blocks can fight each other as their springs try to push them back into position.
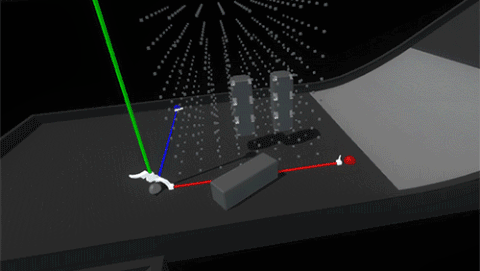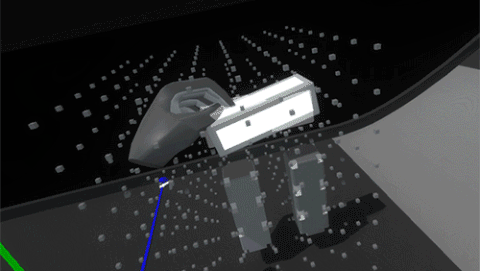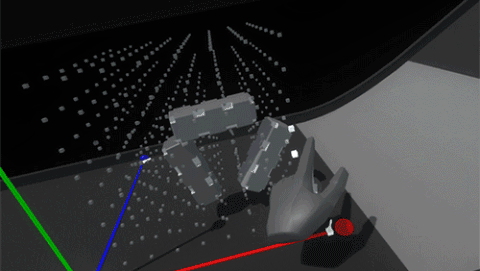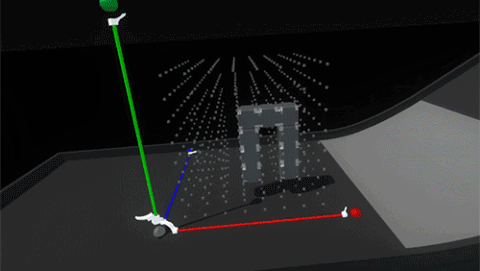
Luckily because we’re in VR we can simply use layers to set blocks in the grid to collide only with hands and not with each other.
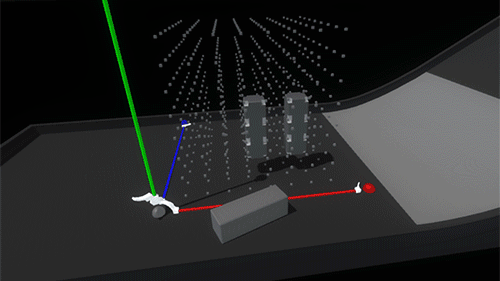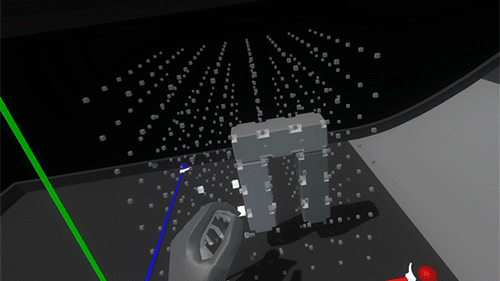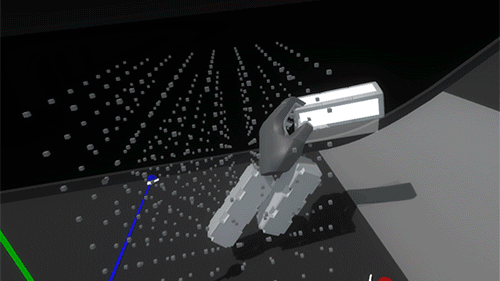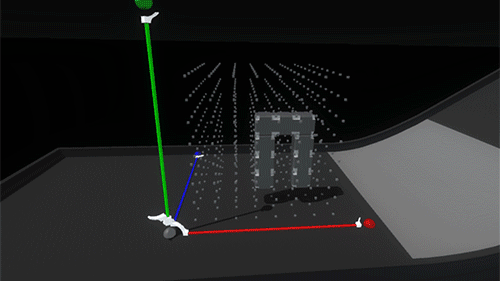
This feels like the right balance of maintaining physicality throughout the interaction without sacrificing speed or accuracy due to collision chaos. Now it’s time to play with our blocks!


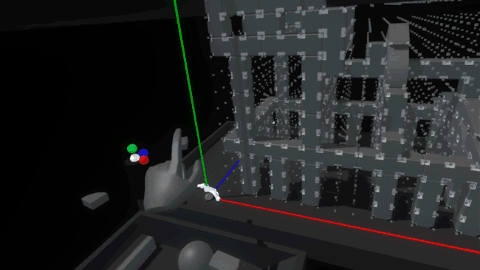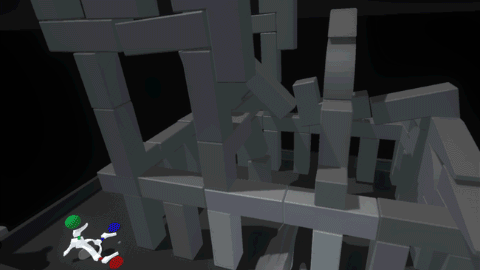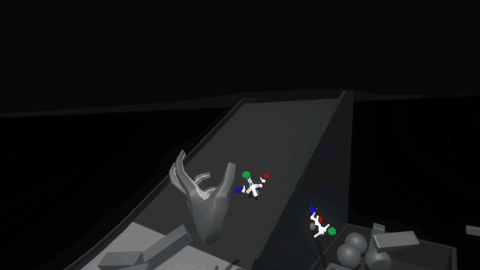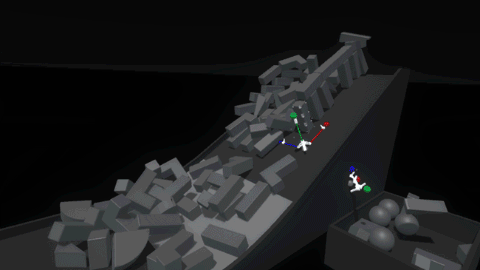


Photo credits: Leap Motion, CanStock, Medium, Google, Sunghoon Jung, Epic Games
An abridged version of this post was originally published on RoadtoVR. A Chinese version is also available.